R como interfaz
R se ha convertido en un lenguaje que no sólo permite hacer análisis (para lo que fue creado originalmente) sino que también se comporta como interfaz para interactuar de forma simple con diversos componentes del ecosistema que debe utilizar un científico de datos. En este blogpost te cuento sobre algunas de las razones por las que este lenguaje se comporta en casi como un lenguaje “low-code” o interfaz útil para realizar una gran variedad de tareas y procesos
Acompañamos en iniciativas y proyectos de ciencia de datos, ingeniería e infraestructura. Visita nuestra página ixpantia y contáctanos.
R
Si estás leyendo esto probablemente sabes qué es R o al menos has escuchado de este lenguaje de programación en algún momento. Sí no, te doy una pequeña introducción a continuación. En 1976 John Chambers creo el lenguaje S, el cual era una implementación de un entorno interactivo de análisis estadístico escrito en Fortran. En 1991, Rossi Ihaka y Robert Gentleman, miembros del departamento de Estadística de la Universidad de Auckland. crearon R, como una reimplementación de S como código abierto. Seguidamente, en 1997, se dio la primera publicación de R, y comenzó una lista de correo para lo que fue el inicio de la comunidad R. Y eso nos lleva a la actualidad, donde R se ha convertido en el lenguaje más popular para la ciencia de datos.
R nació como un lenguaje de programación estadística, es decir, fue creado con la intención de facilitar el desarrollo computacional de pruebas, análisis y visualizaciones estadísticas.
The best thing about R is that it was written by statisticians. The worst thing about R is that it was developed by statisticians - Bo Cowgill
Sin embargo, a través de aproximadamente 26 años la comunidad de R se ha encargado de crear un ecosistema donde la cantidad de herramientas disponibles ha crecido exponencialmente, aumentando así lo que podemos lograr usando R. En este blog post voy a hablar sobre como hoy, marzo 2023, R se ha convertido en una interfaz para interactuar con muchas otras herramientas de forma fácil y eficiente.
El punto de partida
Un equipo de datos puede estar conformado por personas con diversos antecedentes y puestos de trabajo. Por ejemplo, imaginemos una organización financiera en donde un equipo puede estar compuesto por expertos financieros, profesionales de datos, analistas, responsables de riesgo, responsables de caliadd y expertos en mercadeo digital. Todas estas personas pueden tener requerir hacer tareas con código muy distintas entre si: desde usar APIs de distintas indoles, escribir algoritmos en Fotran, C/C## o Python hasta queries en SQL.
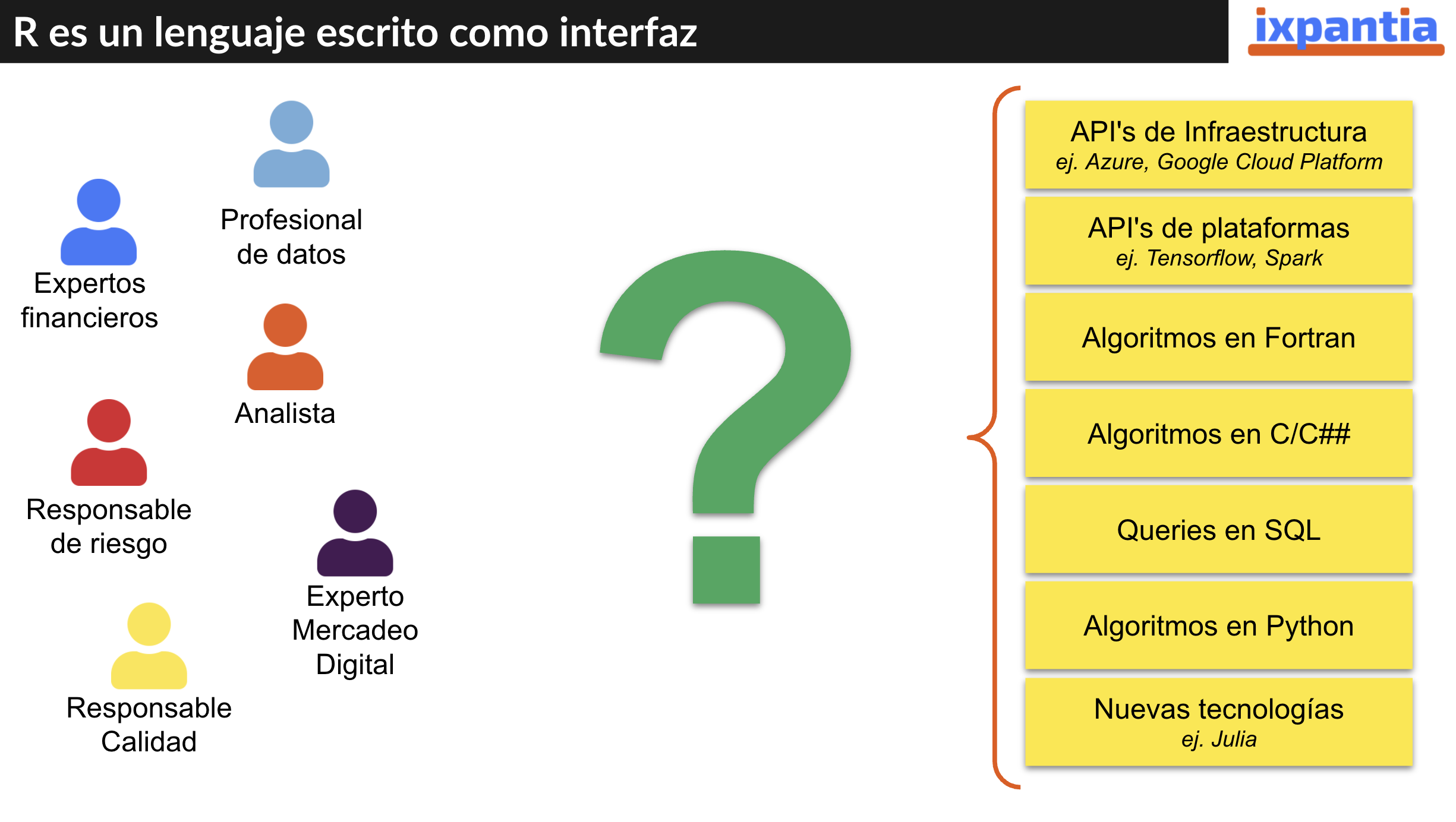{kind=link}
Ahi es donde R brilla, porque puede resolver todas estas necesidades en un mismo lugar, en esencia R es un “wrapper language”, es decir, un lenguaje que “envuelve” otros lenguajes o tecnologías y da una interfaz eficiente y ordenada en común para interactuar con estos.
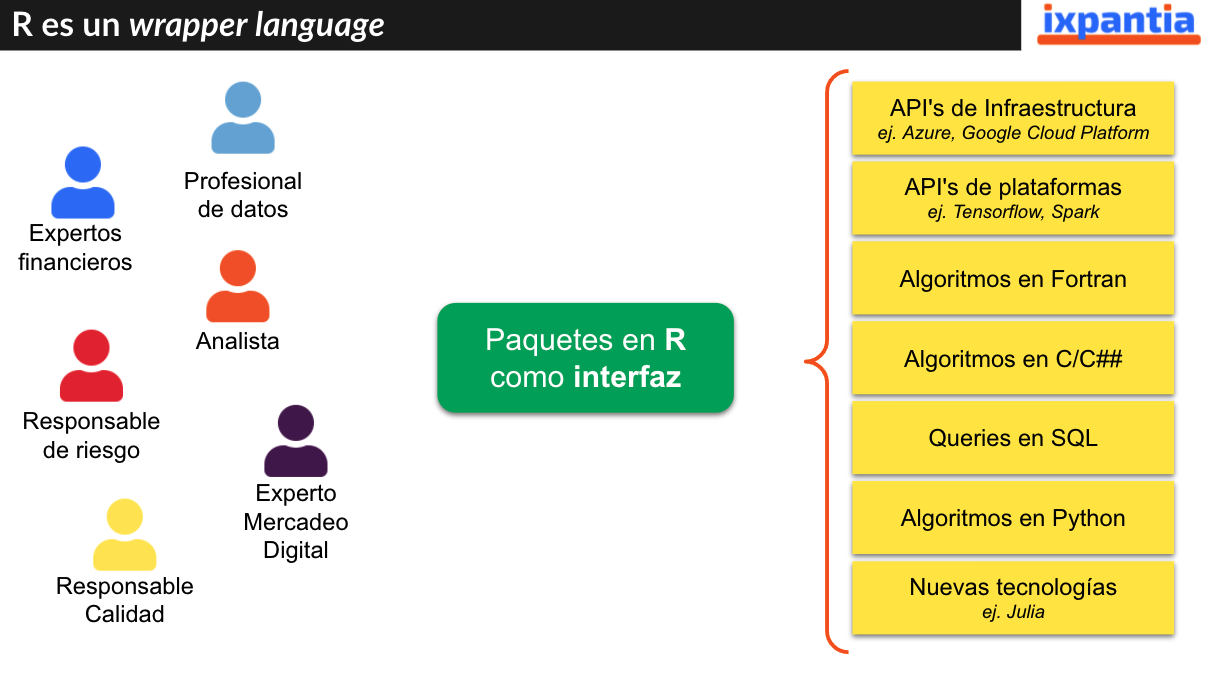{kind=link}
R para ejecutar código fortran
Una importante razón para la existencia y el éxito de R es que abrió la posibilidad de correr código escrito en Fortran de una forma más fácil. Quizás se puede decir que la mayoría de científicos tienen una buena base numérica, pero no son programadores. El poder correr scripts de Fortran y meter sus propios datos de una forma eficiente fué la razón por la cual se d esarrolló el lenguaje S. Hasta el día de hoy hay cientos de paquetes que contienen código Fortran, porque son algoritmos muy maduros y corren de forma veloz.
Quizás has notado que en Windows hay que instalar devtools para poder compilar paquetes de R desde su código fuente. Gran parte de lo que estás instalando allí es un Fortran compiler.
R para ejecutar código C/C++
Análisis numérico necesita poder ejecutar a alta velocidad y usar recursos de cómputo con la mayor eficiencia posible. Por eso solamente se puede sonreír si alguien dice “R es lento”. Para lo que importa para alguien trabajando en datos la velocidad muchas veces se busca en un ejecutable que no está en R, como vimos arriba con Fortran. Hay aún más paquetes que contienen código C/C++. Hay muchos ejemplos:
ranger: una implementación en C de RandomForest
wordcloud: para crear wordclouds n R
geojsonR : para trabajar con objetos GeoJson en R
terra: para hacer análisis de datos espaciales en R
Entre muchos otros.
Y si quieres escribir tu propio código en C/C++ está el paquete Rcpp para hacer el puente.
R para crear APIs
Los APIs son una forma simple, elegante y eficiente de ofrecer un servicio o producto de datos. Y en R la construcción de un API, usando el paquete plumber resulta en un proceso sencillo y sumamente organizado. Empaquetar nuestro código en el formato que plumber propone debería ser un proceso sencillo en la mayoría de los casos.
Una vez que tenemos el código en el formato esperado, su despliegue se puede lograr de muchas formas. Una muy común es a través de contenedores, que luego pueden ser desplegados con una gran cantidad de tecnologías diferentes y luego ser expuesto al público meta sencillamente.
R para interactuar con plataformas de nube
La ciencia de datos cada vez se desarrolla más en plataformas de nube como AWS, Azure o GCP. Cada vez más equipos de datos despliegan sus productos en este tipo de plataformas y por lo tanto, deben aprender a interactuar con ellas de la forma más eficiente posible. Aquí es donde R puede jugar un papel tal vez inesperado para algunas personas.
Para cada una de estas plataformas existe 1 o más paquetes de R que nos permiten interactuar con sus recursos de forma simple. Esto permite que equipos que ya trabajan con R ahora tengan la oportunidad de, desde su mismo entorno de trabajo, desplegar productos de datos e interactuar con otros recursos de la nube.
Algunos de estos paquetes son:
- aws.s3P: para interactuar con Amazon Simple Storage Service
- paws: para interactuar con multiples recursos de AWS
- googleCloudStorageR: para intectuar con Google Cloud Storage
- BigQueryR: para interactuar con el servicio de BigQuery de GCP
- AzureStor: para interactuar con Azure Storage (file, blob y ADLSgen2)
- AzureVm: para interactuar con Azure Virtual Machines
Y estos son solo 2 ejemplos por nube, pero hay muchos más, de hecho el proyecto cloudyr maneja un grupo muy extenso de paquetes para interactuar con estas tres plataformas de nube. Aquí puedes encontrar la lista completa.
Wrappers para APIs
La comunidad de R es sumamente activa y constantemente creando paquetes para conectar R con otras tecnologías. Una forma muy común de hacer eso es creando wrappers para APIs ya existentes, de forma que facilita al usuario la interacción con el mismo y da un puente directo para hacer llamados al mismo desde R.
Ejemplos de este tipo de paquetes hay muchos en R pero adelante menciono algunos interesante así como algunos que hemos desarrollado en ixpantia:
- gh: wrapper para el API de GitHub
- tuber: wrapper para el API de Youtube
- spotifyr: wrapper para el API de Spotify
- openai: wrapper para el API de OpenAI
- gitear: wrapper para el API de gitea
- lacrmr: wrapper para el API del Less Annonying CRM
- googleErrorReportingR: wrapper para el API del Error Reporting de GCP
Si te interesa crear un paquete de este tipo, asegurate de revisar el paquete httr, seguramente será un buen lugar para comenzar.
System calls
Si te interesa comunicarte con alguna herramienta o tecnología que no tiene un puente directo como un paquete o API pero si tiene una forma de comunicación a través de CLI, entonces puedes hacerlo utilizando system calls desde R. Esto te permite escribir instrucciones de terminal dentro de tu código R.
Un ejemplo de uso de este tipo de llamados es utilizarlos para hacer ejecutar comandos de gloud, la herramienta de cli de GCP. Una forma en la que hemos hecho esto en ixpantia es para automatizar el despliegue de servicios de Cloud Run. La forma en la que lo hicimos es que creamos una función de R que tiene como parámetros la organización para la que queremos desplegar el API y esta se encarga de seleccionar la última versión de la imagen adecuada desde el Container Registry, desplegar el servicio en Cloud Run así como modificar los permisos y reglas de firewall deseadas. De esta forma no solo logramos que el despliegue de estos servicios se pueda automatizar por medio de un script que corre diariamente si no que también hacer este tipo de despligue de productos a través de código nos da reproducibilidad y documentación.
Este blog lo mantiene el equipo de ixpantia y la comunidad de gente interesada en datos de la cual estamos contentos de formar parte ¿Tienes una idea para publicar algo aquí? ¡Escríbenos! Estamos siempre interesados en material e ideas nuevas. © 2019-2022 ixpantia