4 DataOps
El proceso de Dataops lo describimos como el proceso desde la concepción de una idea para un producto de datos hasta su puesta en desarrollo. En estos pasos tenemos que tomar en cuenta multiples diferentes facetas desde la interacción humana hasta el trabajo en código para el producto de datos.
Para que los proyectos de datos sean exitosos creemos que debe de hacer un proceso claro, definido y ordenado en donde pueda darse la colaboración, la comunicación en un flujo continuo sin muchas trabas que obstaculicen el trabajo.
Para estos procesos necesitamos saber de gestión de proyectos, de control de versiones, de mejores prácticas para el trabajo con código y tener claro cuáles son los usuarios finales que consumirán nuestro producto de datos para saber cuál es el método ideal de puesta en producción.
Es un proceso en el cual manejamos archivos para la documentación del proyecto como por ejemplo notas de trabajo hasta la documentación del código y un sistema de configuración de proyectos para poder generar tiquetes que delimiten y deleguen de tareas en una forma muy clara.
En su desarrollo del concepto, DataOps viene directamente del moviemento DevOps, donde se buscó acercar a los desarrolladores al mundo de despliegue. Hace 10 años un desarrollador de una aplicacion web podia estar lejos, en tiempo y lugar en la organizacion, de los procesos que llevan al despliegue de la aplicación. Hoy en dia es probable que en el momento que se acepta su solicitud de fusión, esto desencadena un proceso immediato y automatico de pruebas y despliegue.
La gran mayoria de las personas que entramos al mundo de cienca de datos no tenemos este bagaje de conocer la complejidad de despliegue. Estamos acostumbrados a ser bastante autosuficientes, y en general la ingenieria de desplegar y escalar procesos en infraestructura de producción no es parte de lo que conocemos. Es por eso que para muchos si hablamos de DataOps pensamos un proceso que parece complejo y tedioso, pero a la postre es un proceso que asegura el éxito del proyecto si lo llevamos de manera correcta.
Cabe destacar que para este libro somos agnósticos de ideologías de gestión de proyectos y tomamos elementos de varias de la forma más simplificada para facilitar el proceso.
En esta introducción damos un vistazo al panorama que se encuentran muchos equipos de datos dentro de sus organizaciones. En las siguientes secciones ahondaremos más en cada una de las secciones para profundizar en el cómo llevamos a la práctica todo lo mencionado hasta acá.
4.1 Panorama para un equipo de datos
Nosotros visualizamos el panorama para un equipo de datos como la siguiente imagen en donde la otra orilla constituye lo que es ya nuestro producto de datos integrado en el proceso interno de clientes (como llamamos a los usuarios finales). Pero para llegar ahí desde donde estamos necesitamos constituir en primer lugar un equipo de datos, necesitamos desarrollar el equipo que estará trabajando en la creación de esos productos de datos que vamos a entregar.

Para esto necesitamos primero integrarnos en lo que es el día a día de nuestra organización, en los procesos internos que tenemos como unidad o bien como empresa. La organización necesita estar conciente de que existe un equipo de datos y que este puede servir a diversos fines para darle valor a los datos.
El puente lo conocemos como el proceso de entrega. Una vez que tenemos los productos de datos los tenemos que llevar al cliente. Esta es la parte más fluida de todo el proceso (no por esto la más fácil) pero para llegar a este paso ya tenemos establecido internamente toda una gestión interna que nos permite desarrollar productos de datos y además un paquete de trabajo bien delimitado que nos permite satisfacer la necesidad del cliente a quien vamos a entregar.
Un aspecto importante a tomar en cuenta es que comúnmente lo que hacen los equipos de datos puede tener diferentes nombres: analítica, análisis avanzado, inteligencia de negocios. El nivel al que ejecutan tareas de ingenieria de datos y la parte tecnica de desplieuges varia entre diferentes equipos. En aquellos casos donde la parte ingenieril queda en manos de otro equipo es necesario formalizar los procesos de entrega para dar el contexto necesario que se necestia a la hora de desplegar los productos de datos. Es posible tambien delegar esa parte ingenieril a productos como RStudio Connect, donde la persona creando el producto de datos puede desplegar con una solo botón.
Es difícil delimitar con un nombre o una categoría todas las tareas que realizan los equipos de datos y por ende visualizamos esto como un continuo en donde a los extremos tenemos tareas que se parecen más a ingeniería de datos y en el otro tareas que van más acorde a ciencia de datos.
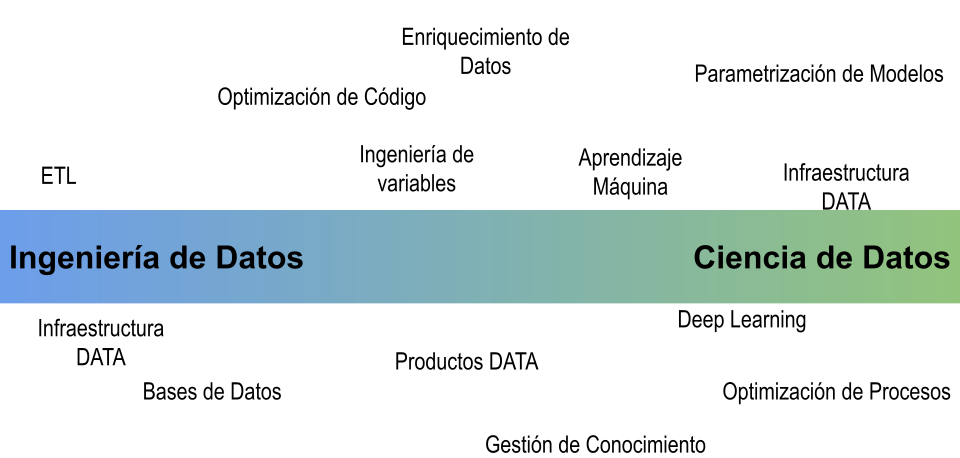
Cabe destacar que los equipos de datos, dependiendo del tamaño de la organización podrían tener recursos especializados o externalizados en el desarrollo de tareas que están más de un lado que de otro. Tipicamente hay por lo menos una persona en el equipo de ciencia de datos que tiene afinidad con todo el ancho de la gradiente, para poder aportar a las discusiones donde es importante entender como despliegue de productos de datos son diferentes a los productos de software tradicionales.
Uno de los principales retos que nos encontramos en las organizaciones es que los equipos de datos están bien capacitados y operando mayoritariamente en tareas que están más del lado de ciencia de datos. En estos casos es importante reconocer que se necesita apoyo del lado de ingeniería. Ademas tenemos que mantener en mente que todo lo que vayamos a desplegar necesita ser incorporado de tal forma que los usuarios finales puedan utilizarlo y comprendan cómo utilizarlo.
4.2 Hábitos de DataOps
El proceso DataOps enfatiza en los siguientes hábitos:
- Comunicación
- Colaboración
- Integración
- Automatización
- Medición de impacto
DataOps parte de la experiencia y desarrollo del concepto de DevOps en donde los ciclos para entregar a cliente se han acortado al eliminar barreras como ciclos muy cerrados donde desarrolladores únicamente desarrollaban, Quality Asurance (QA) se encargaba únicamente de realizar las pruebas y gente especializada en hacer los “builds” para llevar a producción. Todo esto hacía que se demorara meses en que un cambio una vez implementado llegara al usuario final.
El cambio se da en que se trabaja bajo la idea de integración continua, en donde los cambios realizados son pasados a través de pruebas y si estas son pasadas de manera exitosa el cambio es implementado en el proyecto.
Este concepto calza bien con lo que es DataOps donde los requisitos si los tenemos muy bien definidos podemos realizar el proceso de integración continua. El usuario detecta una nueva necesidad que cambia parte de los requisitos, nuestro equipo realiza los cambios si los datos así lo permiten y el ciclo puede darse rápidamente con las nuevas integraciones.
Llegar a esta convergencia implica que necesitamos echar mano de una caja de herramientas que nos permite fluir y hacer entregas muy regulares para que no nos afecte demasiado en caso de que el usuario final nos solicite nuevos cambios. Estos ciclos necesitan ser muy breves y llevar a un resultado sobre el cual se puede decidir si añade valor, y si vale la pena entrar en un nuevo ciclo para seguir con el desarrollo.
En terminos de dominio de DataOps, es una combinación de ingeniería de datos, integración de datos, seguridad de datos y calidad de datos que se engranan con los cinco hábitos mencionados anteriormente.