10 Gestión Codigo
10.1 Introducción
10.2 Introducción a gestión de código
Como profesionales de datos nos vemos en la necesidad de trabajar con código para solucionar problemas y responder preguntas que involucran datos. Sin embargo, la diversidad de profesiones en el campo de ciencia de datos puede tener como desventaja que no hemos recibido una formación en cuanto a lidiar con el código y los productos que generamos con este.
Regularmente vemos prácticas como compartir archivos de código por correo, de tiempo gastado en unir versiones de código en un solo archivo, de pérdida de reproducibilidad o la sensación de que no hay un orden en el flujo de trabajo.
Esta sección trata justamente con esto. Esperamos que al final del segmento gestión de código podamos responder preguntas como:
- ¿Cómo compartimos archivos de código?
- ¿Cómo combinamos mi trabajo en código con el del compañero?
- ¿Cómo reviso el código de otra persona?
- ¿Cómo evaluamos la calidad?
- ¿Cómo generar versiones del código?
- ¿Cómo despliego mis productos de datos?
- ¿Cómo compartir resultados?
Si bien este capítulo puede un tanto técnico de todos, buscamos hacer una introducción para luego entrar en detalles. Si su rol en un proyecto no implica estar tan profundamente relacionado al código, con la introducción tendrá un panorama de las herramientas existentes y mejores prácticas para el flujo de trabajo. Si su rol implica estar fuertemente relacionado con el código, esta introducción y los demás capítulos le serán de gran ayuda tanto para tener el panorama como detalles técnicos.
10.3 Herramientas para la configuración de sistemas
Aquí hacemos introducción a las herramientas para el control de versiones, explicando flujos de trabajo. Para mayores detalles técnicos tendremos los siguientes capítulos.
Para gestionar codigo generalmente trabajamos con un sistema de configuracion de sistemas (SCM por las siglas en inglés de System Configuration Management). Estos sistemas generalmente tienen los siguientes elementos integrados en una sola plataforma.
- Sistema de tiquetes
- Sistemas de documentacion (generalmente un wiki)
- Sistema de gestion de codigo (hoy en dia generalmente git)
- Sistema de gestion de proyectos (por ejemplo alguna implementacion de un tablero kanban)
Los principales jugadores comerciales en este espacio son Github (Microsoft), Bitbucket (Atlassian), GitLab (GitLab). Hay otros que son de fuente abierta como Gitea o Fossil-scm. Todos se parecen mucho, porque tienes los componentes muy parecidos.
En estos capitulos ven imagenes de lo que ixplorer. Esta es en base Gitea, con algunos cambios a las traducción para hacerlo más apto a trabajar con proyectos de ciencia de datos. En ixpantia levantamos una instancia de ixplorer aparte para cada cliente, en un servidor aparte. Al no tener interfaz publica como Github, podemos dar un entorno seguro para cliente que aun no tienen mucha experiencia. Pueden haber errores, pero dificilmente catastrofes. Además como interfaz es suficientemente generica para que reconozcas la funcionalidad en cualquiera de los otros sistemas.
Dentro de estos sistemas git, para la gestión de codigo, tiene una curva de aprendizaje alta. Pero al dominarlo como equipo permite seguimiento y auditoria de cambios que nos es posible de otra forma. Es la funcionalidad de git que permite trabajar con solicitudes de fusión en la herramienta de configuracion de sistemas, por ejemplo. Además, si bien generalmente la interfaz para gestionar tiquetes es fácil de usar, pero la disciplina de usarlos en equipo requiere atención por parte de todos en el equipo.
10.4 Gestión de versiones de código
Git tiene una curva de aprendizaje alta. Al inicio parecerá que es mucho trabajo para realizar cambios en los archivos del proyecto. Esto puede ser cierto pero conforme crezca el proyecto o bien nos encontremos trabajando en más de un proyecto de manera paralela tendremos la paga por haber aprendido git y manejar el código con estas prácticas.
En git contamos con repositorios, ramas, commits y bifurcaciones. Cada uno de los elementos cumple un rol para la gestión del código, entre la más importante es el trabajo de manera asincrónica entre los miembros del equipo.
Imaginemos un escenario en donde existe un taller que ensambla todas las piezas para crear una motocicleta. Las piezas son traidas de diferentes talleres que han estado trabajando en la construcción del motor, la construcción de las luces y componentes eléctricos y otro taller que trabajó en la construcción de las piezas como manillas y asiento.

Lo ideal es que todos los talleres tengan un punto de referencia común durante la construcción por separado de cada uno de las piezas para que durante el ensamblaje todo calce a la perfección sin ningún contratiempo.
Algo similar ocurre cuando estamos escribiendo código en equipo. Cada uno esta construyendo una pieza, o serie de piezas, que tienen que calzar el codigo de todos los demás. Para que esto suceda tambien necesitamos tener ese punto de referencia común y en el contexto de git lo solemos llamar el repositorio madre, y por convención le damos el nombre upstream en inglés. Cada uno de los miembros que va a trabajar en las distintas piezas tendrá una copia de este repositorio madre, y esa copia será conocida como una bifurcación.
El taller de cada uno de los miembros donde tendrá sus herramientas de trabajo tipicamente será su propia computadora. La bifurcación que al momento de crearlo existe remoto, en la herramienta de configuración de proyecto, la clonarán en su computadora. De esta forma si ocurre un accidente en el taller de cada uno, no afectará el trabajo de los demás. Ademas podemo calzar piezas en nuestro propio taller, y si no calzan se quedarán en el computador local hasta que sea enmendado.
Tomemos como ejemplo la construcción de las luces y el sistema eléctrico. Esto se hace paso a paso. Cada uno de los componentes se puede dividir en tareas más específicas que juntos forma un paquete de trabajo - un conjunto de tareas que le podemos asignar a alguien. Por ejemplo se puede iniciar con el cableado, luego las conexiones a la fuente de energía y la validación de que la corriente eléctrica fluye por los cables con el voltaje adecuado. Luego de medir que el voltaje es el adecuado se procede a conectar el bombillo para validar que este funciona. Por último se ensamblan todas las piezas juntas y con esto terminamos el proceso para entregar el sistema de luces y eléctrico.
Como vemos hay muchos pasos en la construcción de este componente de la motocicleta. Y al tener la posibilid de crear tiquetes podemos definr tareas para conectarlas con las piezas de codig que vamos entregando. Cada una de estas tareas las trabajamos en lo que conocemos como ramas en git. Una rama es un conjunto de cambios que podemos ofrecer para inclusión en el repositorio madre cuando finalizamos la tarea.
Todo este esfuerzo para separar en algo reconocible lo que cada participante en el desarrollo contribuye tiene varias ventajas. Primero nos permite incluir un proceso para garantizar la calidad del código compartido. Y además nos da la posilidad de regresar a un estado anterior cuando por un dedazo o error incluimos código que no corre. Si tenemos en una rama diferente una tarea que daña el código podemos volver a la rama que tiene el código que estaba funcionando sin haber dañado nuestro propio flujo de trabajo. En la analogia con el taller, es como si el reguero quedó en una esquina del taller y no sobre todos nuestros componentes.
10.5 El github workflow
En esta sección queremos hacer una introducción a través de un mapa conceptual sobre el flujo de trabajo con git. Los pasos acá enumerados serán descritos de manera conceptual y los detalles técnicos serán explicados en sub-capítulos posteriores. Tomen nota de que proponemos los que llaman el github workflow, basado en bifurcaciones personales. Hay otras forma de trabajar, con otros roles y nombres para las ramas, pero solo mencionamos esta porque es la que en nuestra experiencia es la que mejor funciona para evitar errores.
10.5.1 Elementos básicos
Para trabajar con este flujo de trabajo necesitamos poder identificar los siguientes componentes.
- La carpeta de trabajo: Un directorio (carpeta) en tu computador local donde recide el codigo del proyecto de análisis de datos que estas trabajando.
- git: El software que usamos para poder la gestion y control de versiones de codigo.
- Un IDE: Generalmente el entorno de desarrollo que usar, como RStudio, requiere uno o varios archivos para definir el proyecto.
- Un repositorio: Un repositorio en ixplorer (o su sistema de configuracion de proyecto favorito)
10.5.2 Repositorio central (upstream) y bifurcaciones
El primer concepto que tenemos que entender es que como equipo de trabajo vamos a tener un repositorio central bajo el cual almacenaremos todo el código limpio, funcional y revisado. Es el centro de acuerdo del equipo.
Desde este repositorio todos los miembros del equipo crearán una copia a la cual llamaremos bifurcación
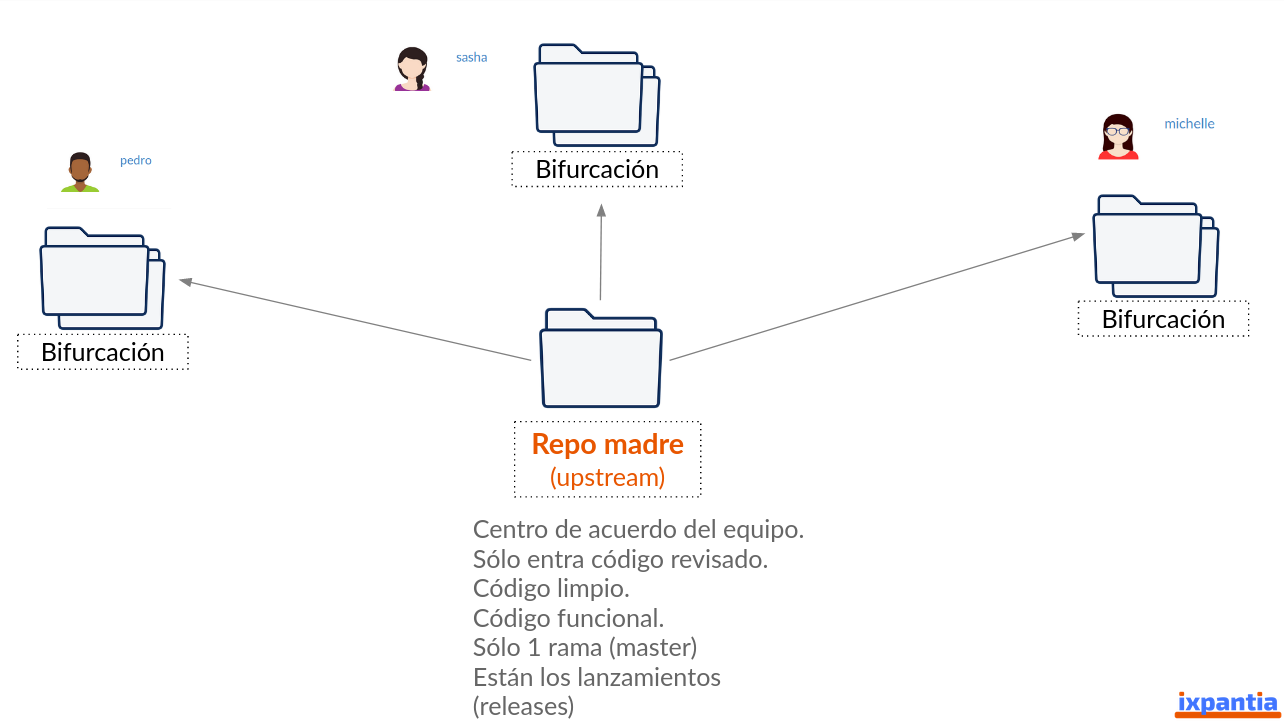
En el repositorio madre (upstream) solo tendremos una rama (master) y además estarán los lanzamientos de versiones oficiales del proyecto.
A este punto únicamente hemos realizado acciones en el entorno ixplorer, no hemos realizado ningún paso en nuestro computador local.
10.5.3 Repositorio local (clonar)
Una vez que hemos generado nuestra bifurcación, queremos traer el repositorio a nuestro computador. A este paso le llamamos clonar. Cuando estamos en el entorno, bajo nuestra bifurcación podemos buscar la opción de clonar.
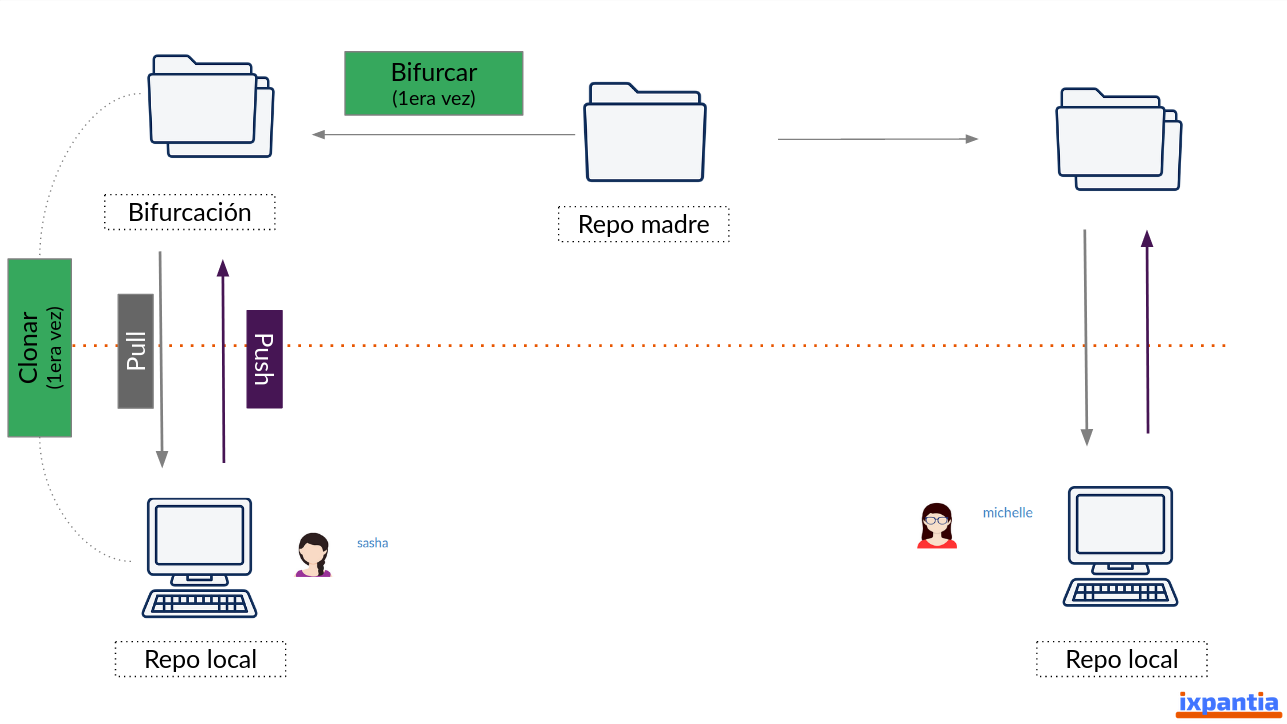
Cuando hayamos clonado el repositorio en nuestro computador, tenemos la posibilidad de generar nuevas ramas y trabajar los archivos del proyecto bajo ramas. El concepto de ramas lo daremos con detalle más adelante, pero a este punto necesitamos comprender que la rama master tiene que ser fiel reflejo del estado del repositorio madre (upstream)
Con el repositorio clonado en nuestro computador podemos entrar en el flujo de trabajo e ir empujando (push) los cambios hacia nuestra bifurcación, hasta el punto en el que estemos listo para entregar nuestro trabajo al resto del equipo
10.5.4 Solicitudes de fusión
Arriba, en el ejemplo sobre la construccion del cableado, lo llamamos un paquete de trabajo. Y en el momento en que hemos finalizado nuestro paquete de trabajo, necesitamos entregarlo al resto del equipo. Entregarlo al resto del equipo significa que debemos de llevar nuestros cambios que ya están en nuestra bifurcación hacia el repositorio central.
Este paso se llama Solicitud de fusión y se hace en dos partes. La primera consiste en que uno mismo seleccione el trabajo que ha realizado y quiere llevar al repositorio central. Se hace la solicitud de fusión y se asigna a un compañero del proyecto para que se encargue de revisar la solicitud de fusión.
El proceso de revisión lo describimos en los siguientes segmentos desde el punto de vista de quién realiza la revisión y acepta o rechaza los cambios. Toma nota que no hacemos una solicitud de fusión de tiquete en tiquete. Esto porque se hace dificil de hacer una revisión del conjunto de cambios que estas entregando. En ve de eso, arrancamos con una nueva rama sobre la cual podemos ofrecer cambios para cerrar varios tiquetes. Hacemos referencia a todos los cambios y a lo que logramos cerrar en la descripción de la solucitud de fusión.
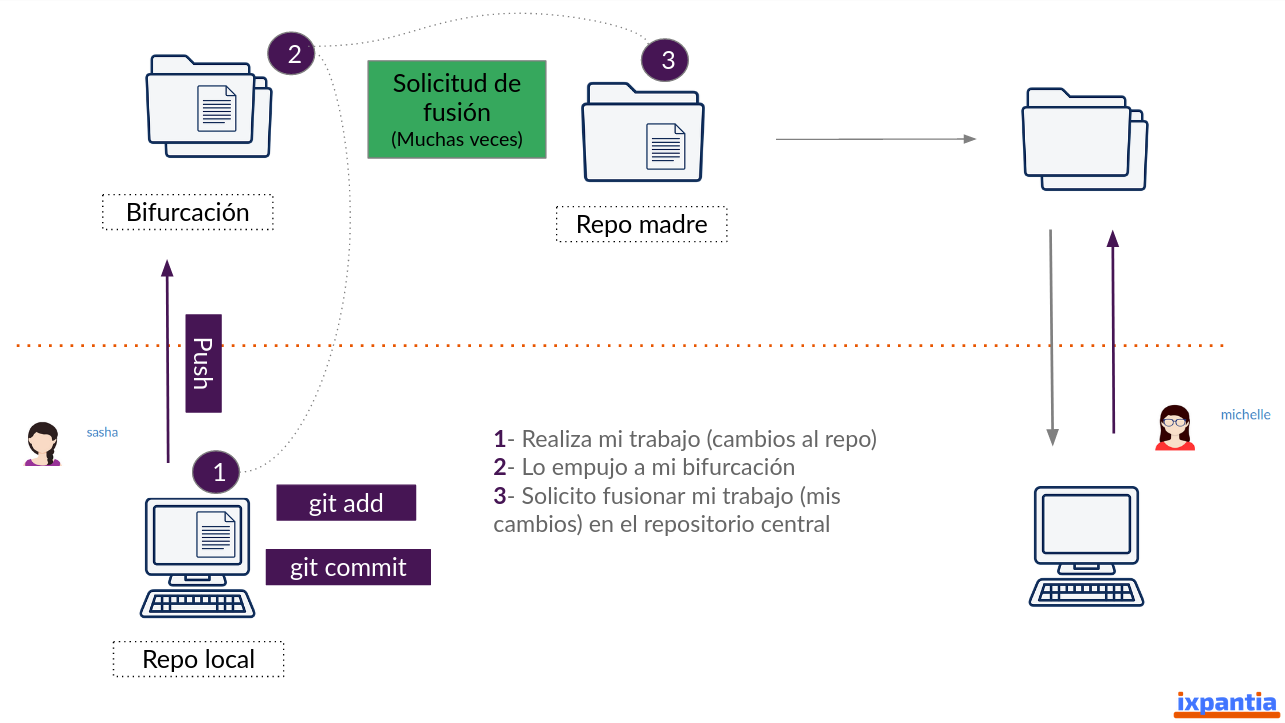
Este compañero tendrá la potestad de aceptar o rechazar los cambios, de acuerdo a la calidad del código y su funcionalidad. Recordemos que el repositorio madre es el centro de acuerdo de todo el equipo y por ende necesitamos que el código sea una entrega correcta.
Si los cambios son aceptados, el código quedará incorporado al repositorio madre y en este momento los demás miembros del equipo podrán actualizarse e incorporar dichos cambios en sus repositorios locales y bifurcaciones.
10.5.5 Actualizar el repositorio
Si un compañero de equipo ha entregado sus cambios en el repositorio central, nosotros necesitamos actualizar nuestro repositorio. Para esto se necesita realizar tres pasos: fetch, rebase y push.
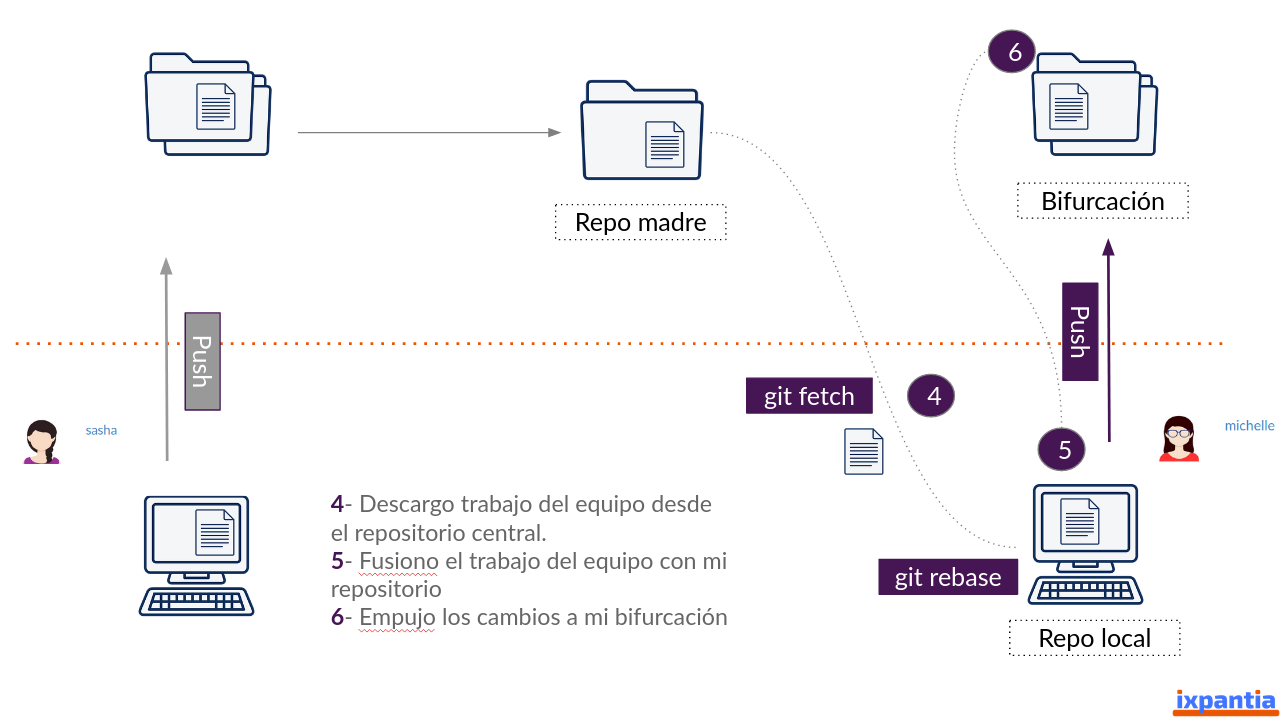
Los pasos son
#Valida si tienes upstream:
git remote -v
#si no, añade upstream
git remote add upstream <URL Repositorio Madre>
#Ahora trae los cambios de upstream
git fetch upstream
#Aplica los cambios upstream a tu propia rama master
git checkout master
git rebase upstream/master
git pushEl fetch nos descargará los cambios que se encuentran en el repositorio madre, pero no los combinará de manera inmediata con nuestro trabajo. Para integrar estos cambios en nuestro repositorio necesitamos del rebase el cual se encarga de fusionar los cambios localmente. Una vez que el rebase ha hecho su trabajo, tenemos que empujar esta actualización a nuestra bifurcación por lo que realizamos un push.
En el dia a dia - cuando ya has hecho los pasos para verificar si tienes el upstream configurado, como mostramos arriba - se hace más breve los pasos.
#Trae los cambios de upstream
git fetch upstream
#Aplica los cambios en upstream/master a tu propia rama master
git checkout master
git rebase upstream/master
git push10.6 Revisión de código
Anteriormente mencionamos que una entrega de trabajo se finaliza haciendo una solicitud de fusión. Ahora abordaremos el tema desde el punto de vista de quién está encargado de revisar la entrega del trabajo para ser aceptado o rechazado en el repositorio madre (upstream) del equipo.
Tengamos en cuenta que una solicitud de fusión (SF) es una entrega de trabajo (tiene principio y fin) y es algo que está listo para ser revisado.
Una SF debe de ir acompañada de un pequeño change log (bitácora de cambios). El mínimo de contenido es el listado de numerales de tiquetes solucionados o trabajados (para tener la referencia).
La revisión de una SF debe de consistir en mirar el cambio completo para dar comentarios. Unos checks basicos son:
- ¿Están cerrados los tiquetes marcados en el comentario de la SF como cerrados?
- Importar el código a nuestro computador local para correrlo y validar que funciona.
- Validar que se adhiere a nuestro estilo de código. (más en la siguiente sección)
- Dar comentarios a través de ixplorer donde es relevante
10.6.1 Pasos siguientes
Lo que hemos visto con estos esquemas nos ayudará a no perdernos cuando nos encontremos trabajando con los detalles técnicos de git. Recuerde regresar a este esquema si no está seguro de porqué está dando algún paso en git.
A este punto no hemos mencionado nada sobre Estilo de código, un tema muy importante que nos enseñará a cómo generar código que pueda ser leído por la computadora y más importante aún: humanos. Un aspecto importante al trabajar como desarrolladores es que no queremos código spaguetti difícil de depurar, escalar o leer. Nada hacemos con tener un control de versiones y repositorios ordenados si en un futuro (lejano o cercano) no sabremos decifrar qué escribimos y porqué.
Luego de haber dominado este tema, pasaremos al flujo de trabajo con git con todos sus detalles técnicos.