5 Gestión de proyectos en DataOps
5.1 Introducción
Para trazar una ruta de principio a fin en u proyecto de ciencia de datos, debemos de tener claro cuáles herramientas tenemos a mano para poder llevarlo a cabo. Herramientas son importantes porque la elaboración y la ejecución de un proyecto tendrá muchas aristas para trabajar, que si no sabemos cómo encausar los esfuerzos, se nos podrá salir de la manos el control.
La complejidad de trabajar en proyectos en ciencia de datos es que cada vez abunda más la información por la diversidad de personas que encuentran soluciones con datos, hay una creciente diversidad de productos y tecnologías, sistemas de almacenaje y además de actividades interdisciplinarias.
//TODO: Desarrollar más la introducción
5.2 Círculo virtuoso de proyectos de datos
Para ayudar a levar a cabo un proyecto en ciencia de datos de principio a fin, hemos definido lo que llamamos el círculo virtuoso de proyectos de datos que contiene los pasos desde la detección de la necesidad hasta la entrega del resultado. Este resultado lo llamamos un producto de datos que puede ser una informe, una conjunto de datos, un modelo de aprendizaje maquina entrenado, un tablero (dashboard) o cualquier otro entregable definido en los objetivos del proyecto.
Es un círculo ya que, si bien un proyecto tiene un final definido, el producto resultante puede llevar a descubrir otras necesidades que nos harán iniciar un nuevo proyecto a partir de la base que ya tenemos.
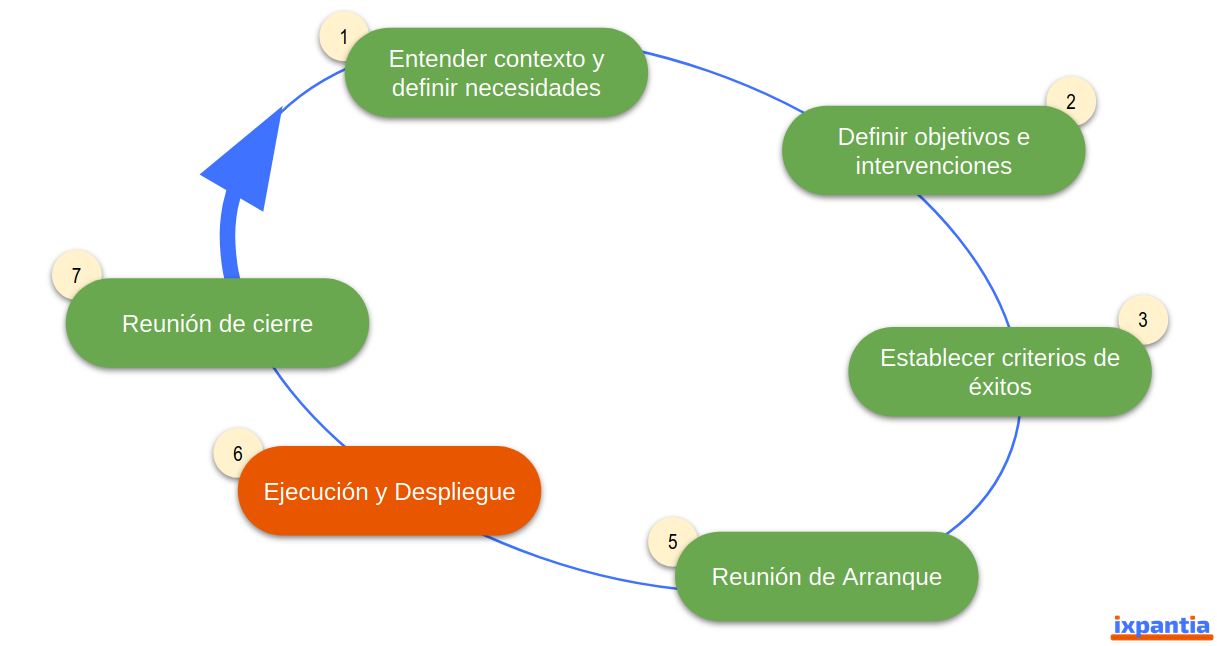
5.2.1 Etapas del círculo virtuoso
- Entender cotexto y necesidades: En este punto nos encontramos iterando a a través de reuniones con los clientes del proyecto (quienes usarán el producto final) para comprender cuáles son sus necesidades. Toma en cuenta que por cliente no nos referimos necesariamente a alguien externo a nuestra organización (puede ser otra área de nuestra propia organización) sino a quién el producto de datos le va a resolver un problema.
- Definir objetivos e intervenciones: Una vez con la comprensión de la necesidad, establecemos los objetivos que queremos cumplir con las acciones a desarrollar en el proyecto. Es muy probable que no podamos satisfacer todas las necesidades del usuario final pero está bien definir pasos pequeños que podamos cumplir. Por intervenciones nos referimos a que nuestro producto de datos va a causar un cambio en el flujo de trabajo del cliente ya que lo incorporará a sus prácticas diarias.
- Establecer criterios de éxito: Antes de iniciar es esencial establecer los criterios de éxito. Esto es en conjunto con el cliente y básicamente es responder la pregunta: Si hacemos bien el producto de datos, si lo logramos, ¿Cómo podemos evidenciar que lo hicimos bien? Es definir métricas que podamos utilizar para medir qué tanto cumplimos con el proyecto.
- Reunión de arranque: Una vez definidos los pasos anteriores (que pueden ser varias iteraciones) plasmamos todo en un documento que nos sirva para una reunión de arranque. La reunión de arranque es justo una reunión donde están los involucrados (stakeholders) del proyecto y aprueban dar el banderazo de salida para el proyecto. Es una especie de contrato donde verificamos que todos los puntos discutidos están claros para todas las partes.
- Ejecución y despliegue: Esto corresponde a todas las actividades que se desarrollan para lograr finalizar el producto de datos planificado. Tiene un color diferente a los demás bloques ya que este contiene un proceso interno que desarrollaremos más adelante para explicar con detalle cómo organizamos toda la serie de esfuerzos que conlleva una ejecución.
- Reunión de cierre: Al estar finalizado el producto de datos llegamos al punto de la entrega en donde presentamos los resultados del proyecto de acuerdo a los objetivos planteados y los criterios de éxito alcanzados.
Es importante destacar que cada uno de los pasos anteriores conlleva a la producción de documentación tanto interna como externa a nuestro equipo de trabajo.
5.2.2 ¿Cuál es la razón de este ciclo?
El orden que nos permite tener los pasos anteriores no da la oportunidad de tener una mayor cantidad de procesos paralelos dentro de nuestro flujo de trabajo que surgen a partir de las nuevas ideas o experimentos que da el proyecto inicial.
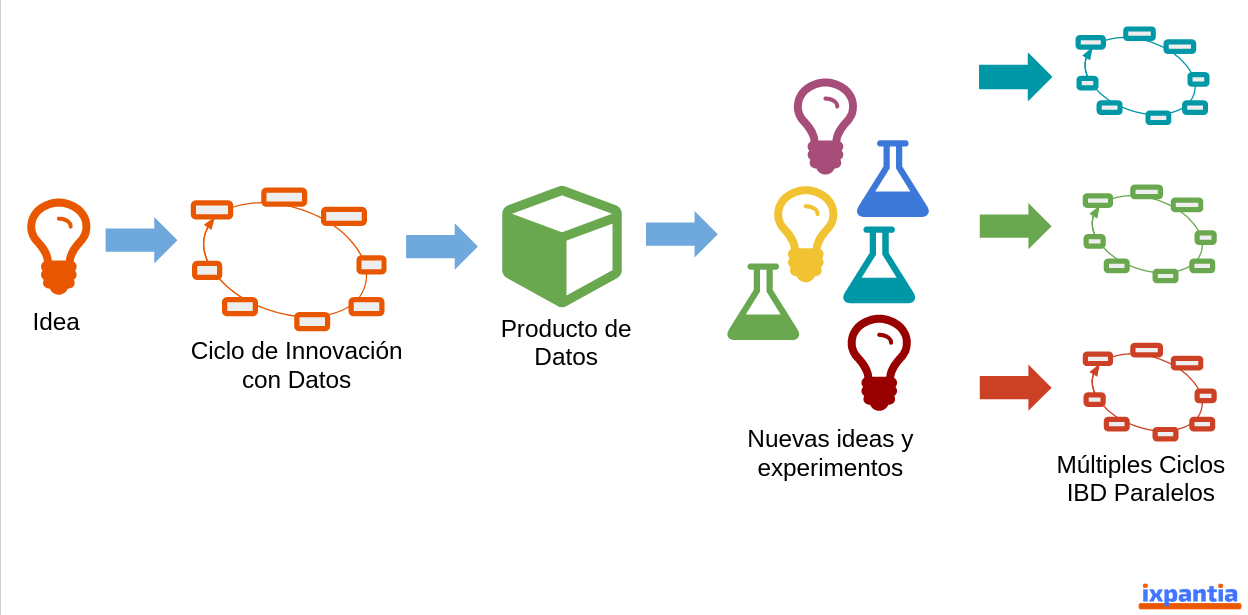
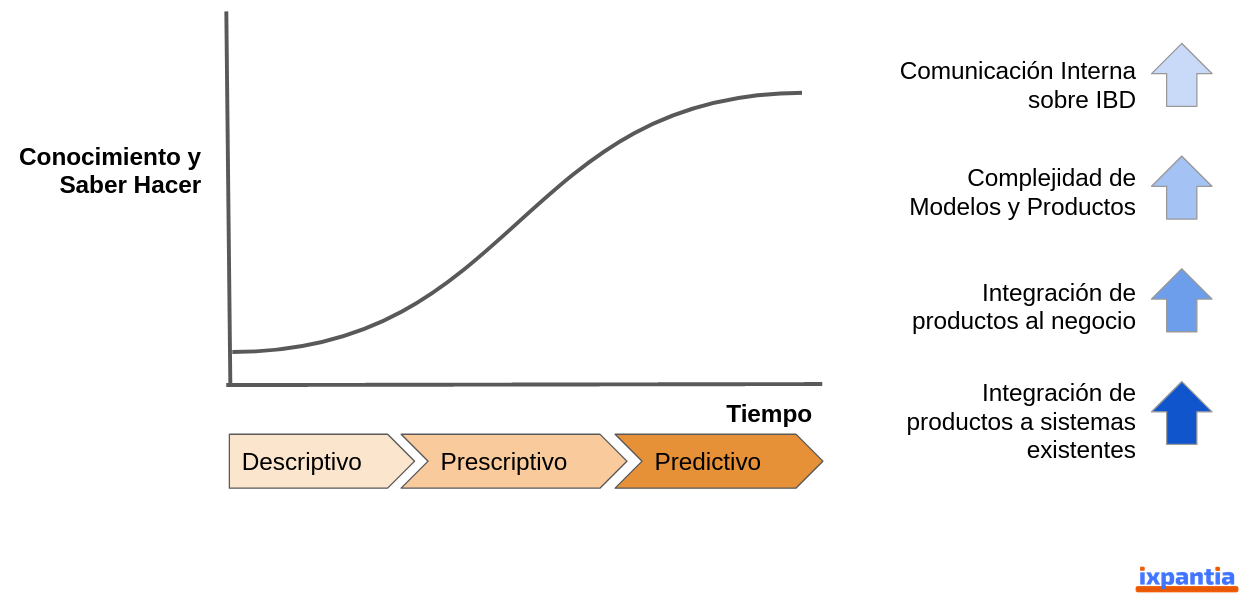
Hay además una fuente de complejidad en el tiempo y lo que muy probablemente sucederá en cada organización una vez que inician sus proyectos de datos es que si bien se inicia con proyectos que pueden ser muy descriptivos, una vez que ese conocimiento está generado, cada vez más van a llegar proyectos donde hay que preescribir cómo gente tiene que valir resultados y por último en complejidad llegar a proyectos de datos predictivos que necesitarán integrarse a sistemas o productos ya existentes, con productos dentro del negocio y mayor complejidad que nos obligarán a que tengamos una mayor comunicación interna.
5.3 Ejecución y despliegue
Este es un punto que es necesario que contenga un apartado para desarrollar los pasos que se deben de llevar a cabo. Si recordamos el círculo virtuoso de los proyectos de datos tenemos que hay un sexto paso justo luego de la reunión de arranque que corresponde a la ejecución y despliegue.
¿Cómo podemos encauzar los esfuerzos del equipo para cumplir con el proyecto?. No es fácil lograr coordinar a un equipo, ideas que vienen y van, posibles pivotes del proyecto y gestionar las expectativas del cliente. Por ende hemos desarrollado un concepto de cómo llevar a cabo esta parte del proceso de un proyecto de datos.
Para ubicarnos en donde está enmarcado la ejecución y despliegue tenemos el siguiente esquema:
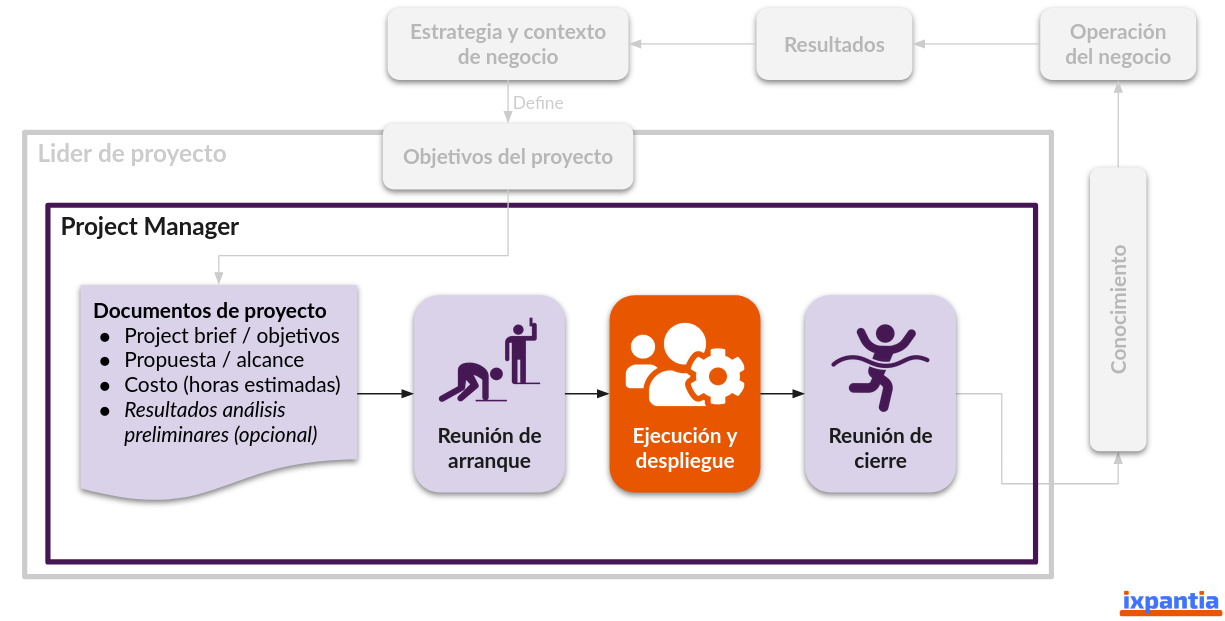
A este punto debemos de tener claros los objetivos del proyecto y contar con documentación que contemple:
- Resumen del proyecto
- Objetivos
- Propuesta con el alcance (y lo que queda fuera de alcance)
- Costo
- Resultados de análisis preliminares (resultado de iteraciones iniciales)
Dado el banderazo de salida para el proyecto necesitamos iniciar con el proceso de ejecución, que tiene etapas e iteraciones. No es un proceso fácil de definir y puede variar para adaptarse a necesidades de cada organización, pero sí es necesario mantener claro que mucho recae en la comunicación mediante la documentación.
5.3.1 Flujo de trabajo para la ejecución y despliegue
Hasta este punto hemos hablado de manera macro los pasos a contemplar para el desarrollo del proyecto y aquí ahondamos en los pasos que existen dentro de esta etapa de ejecución y despliegue.
Para que la ejecución sea fluida, los esfuerzos para delimitar tareas, concluir tareas y presentar resultados intermedios satisfactorios deben de estar muy bien comunicados con el equipo de desarrollo y los demás actores del proyecto.
De nuevo, existen muchas metodologías que se pueden aplicar para gestionar un proyecto, pero de acuerdo a nuestra experiencia con clientes en Latinoamérica, lo ideal es adoptar un modelo minimalista para cortar gastos de energía en aspectos que tienden a hacer más complejo el desarrollo para invertirla en las tareas que son esenciales para el éxito del proyecto.
Los elementos que hemos identificados como básicos van a tener un punto central que es el sistema de configuración del proyecto. Para DataOps este va a ser un sistema donde integramos código, documentación y delegamos tareas al equipo de tal manera que la comunicación asincrónica pueda realizarse. Este sistema deberá de usarse con el sistema de control de versiones git cuyos detalles los abordaremos en mayor profundidad en el capítulo de Gestión de código
Siguiendo el esquema a continuación, tenemos el detalle de la fase de ejecución y despliegue. Al lado derecho se muestran los elementos que están mayormente relacionados con el equipo desarrollador (Líder del proyecto y profesionales de datos) mientras que del lado izquierdo están mayormente ligados a los líderes del proyecto (Interno y cliente) y profesionales de negocio.
Esta división también propone que del lado derecha conlleva una parte mucho más técnica y relacionada al código y tecnología, mientras que del lado derecho tenemos elementos que tienen mayor peso en la comunicación del avance del proyecto junto con sus resultados intermedios.
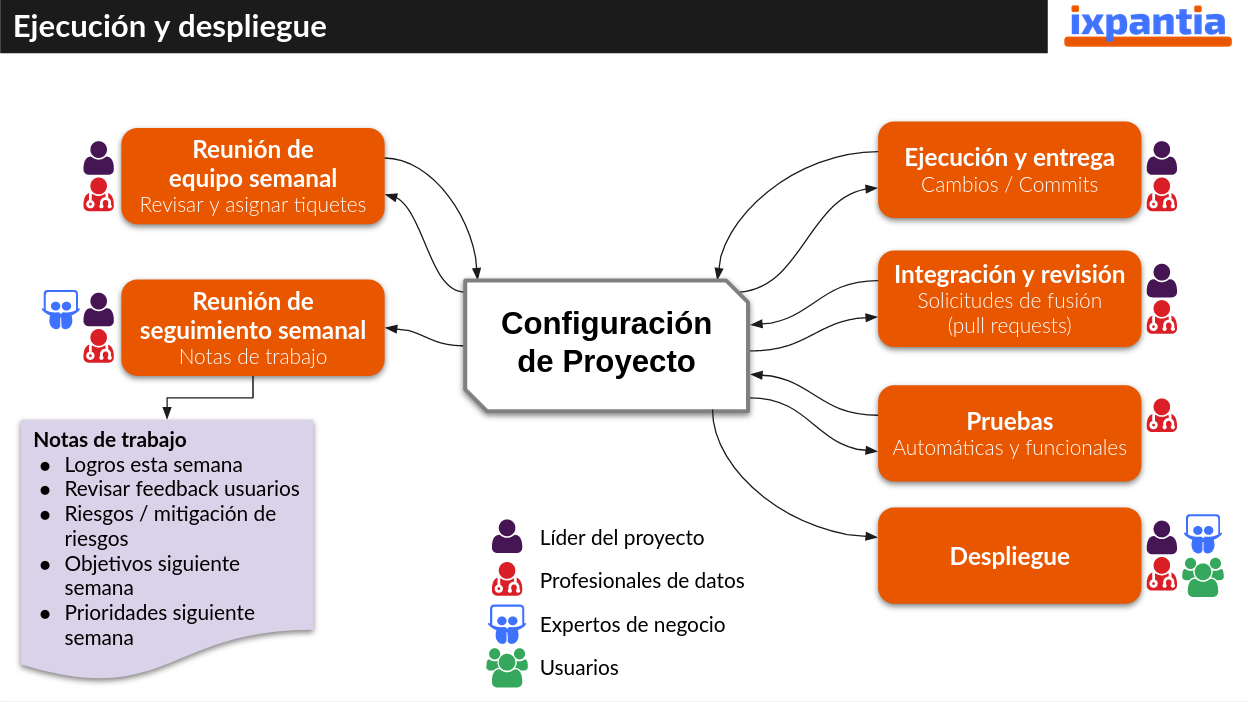
Al tomar en cuenta esta semi-división (lo llamamos así porque ambos lados deben de estar bien coordinados entre sí), vamos a encontrarnos con instrumentos y roles designados.
TODO:// Generar los links de cada uno de los segmentos a la parte del libro donde se discuten con mayor profundidad.
De manera breve explicamos cada uno de los elementos mostrados en el gráfico y dejamos las explicaciones con mayor profundidad para capítulos posteriores.
Ejecución y entrega
- Esta fase es técnica y corresponde a los profesionales de datos el ejecutarla. Al trabajar en archivos con código es necesario el uso de git con un determinado flujo de trabajo, en donde los cambios realizados a los archivos sean controlados a través de commits, cuyo desarrollo y finalización de la tarea es entregada en el repositorio central a través de una solicitud de fusión cuya revisión debe de asignarse a otro miembro del equipo.
- Los que nos permite el sistema de control de versiones git es que los cambios sean registrados como puntos históricos en el proyecto ordenados a los cuales podríamos retornar si así lo quisieramos. Así mismo, cada conjunto de cambios que el equipo crea en el código quedan como un paquete de cambios documentados en su razón de ser.
Integración y revisión
- De nuevo, esta es otra fase técnica cuya responsabilidad es de los profesionales de datos. Cuando un miembro es designado para aceptar o rechazar una solicitud de fusión
- Una vez revisado el código y la documentación entregadas mediante la solicitud de fusión, el miembro del equipo designado procede a aceptarla y fusionarla con el código de repositorio central (donde siempre debe de estar el código limpio y funcional) o bien rechazar los cambios con los comentarios indicando el porqué del rechazo y las correcciones a realizar previo a ser fusionados en el repositorio central.
- El objetivo de la revisión es que dos cabezas piensan mejor que una y esto puede evitar que cambios en el código del proyecto sean desastrozos y generen atrasos en el proyecto.
Más sobre solicitudes de fusión en el capítulo [xxx]
Pruebas - Al desarrollar código para crear funciones y procesos de limpieza y análisis de datos siempre estamos probando que este funcione. Estas pruebas las hacemos en un principio de manera informal ya sea revisando que el código corre y no arroja errores o bien impriendo resultados y corroborando que están correctos. Estas pruebas son valiosas ya que llevan una lógica consigo de condiciones que deben de cumplirse para asegurar que lo que pensamos es lo que nuestra computadora ejecuta. - Estas pruebas las podemos formalizar, creando código que ejecuta dichas condiciones y verifica que sean cumplidas. - El objetivo de las pruebas automáticas es que cada cambio que generemos en el código pueda verificarse su correcto funcionamiento sin perder tiempo en correr uno mismo segmentos de código paso a paso. Esto nos lleva eventualmente a asegurar la calidad del código.
Más sobre pruebas en el capítulo [xxx]
Despliegue
- De acuerdo a la necesidad del cliente, el despliegue comprenderá diferentes elementos, ya sea llevar el producto de datos a un API, una aplicación en producción o bien, un análisis que ejecuta localmente.
- Esa necesidad del cliente debe de estar bien identificada, para así dar las mejores recomendaciones. Estas recomendaciones deben de ser planteadas desde varios planos con las ventajas y desventajas que puede implicar cada una.
- Si es la primera vez que el cliente va a desplegar un producto de datos, lo ideal es que se realice en una primera fase con el menor gasto de dinero posible. El llevar a producción siempre tiene aspectos que no se toman en cuenta, desde nuevas necesidades que surgen (hay más ideas de uso del producto) o bien hay fallos que pueden ser corregidos. El nivel de despliegue debe de planearse en una primera fase de prueba y cuando esa fase esté cumplida (porque se validó que trabaja bien), se puede plantear una segunda fase que contemple nuevas características del producto de datos e inclusive la compra de licencias de software que mejoren la experiencia.
Reunión de equipo semanal
- En esta reunión se involucran los profesionales de datos que están desarrollando el proyecto y el lider del proyecto. El espacio se usa para hacer un repaso por los tiquetes abiertos y cerrados para establecer prioridades, delegar tareas, buscar soluciones a atrasos de tareas (si las hay) y crear tareas que deben de quedar documentadas en el sistema mediante los tiquetes.
- Todos los acuerdos deben de quedar documentados con nombres de personas encargadas, fecha límite de entrega, descripción de la tarea y con la certeza de que se tienen los elementos necesarios para el desarrollo.
- La reunión de equipo semanal tiene por objetivo comunicar de una manera más ágil entre el equipo el avance de las tareas, así como dificultades técnicas que pueden presentar algunas tareas en las que al hablarlas posiblemente otro miembro del equipo tenga la capacidad de ayudar y dar una solución a la persona designada a la ejecución de dicha tarea.
Más sobre tiquetes y tareas en el capítulo [xxx]
Reunión de seguimiento semanal
- Esta reunión tiene por definición que contar con la presencia de los líderes del proyecto: el lider por parte del equipo de desarrolladores y el lider por parte del cliente. Más personas fuera de los líderes, si bien pueden aportar, son extras.
- Una reunión de seguimiento es breve y debe de ser de máximo 30 minutos. En esta se abarca el estado del proyecto, a través de un documento que contenga los logros desde la reunión anterior (logros en 1 semana), los objetivos de la siguiente semana (hasta la siguiente reunión de seguimiento), el plan del proyecto con su estado actual (diagrama de Gantt) y un repaso por los objetivos y entregables del proyecto con las fechas pactadas en la reunión de arranque.
- El objetivo de la reunión de seguimiento es gestionar las expectativas de ambas partes (equipo desarrollador y cliente) sobre el avance del proyecto y el cumplimiento de los objetivos. Es muy necesario gestionar las expectativas ya que puede darse que en la fase de planeación del proyecto se desee llegar a un modelo en particular, pero conforme se desarrolla el proyecto los datos pueden no ajustarse al modelo planeado y por ende hay que pivotear la idea. Si esto no se discute de manera regular con el cliente puede llevar a malentendidos y dar la imagen que es por incapacidad del equipo cuando la realidad es otra. Así mismo, todo proyecto conlleva pasos que no dan resultados palpable de cara al cliente pero que en sí son pasos muy laboriosos a nivel técnico y de código que de nuevo, no se contemplaban al inicio del proyecto hasta ya entrada la fase de ejecución.
TODO:// Hacer link al anexo con el machote del documento.
5.4 Roles en proyectos de datos
Cuando hablamos de roles en los proyectos tenemos que tomar en cuenta que hay dos vertientes de tareas en las cuales van a incurrir y en donde pueden tener más peso en una que en la otra.
- Tareas de la configuración del proyecto
- Tareas en la gestión del código
La vertiente de configuración del proyecto corresponde a aquellas actividades que están relacionadas con las metas y el cumplimiento de los objetivos del proyecto mediante el establecimiento de tareas y comunicación.
La vertiente del gestión del código está relacionado con la ejecución meramente del desarrollo de las tareas relacionadas al código que llevan a la construcción de la limpieza de datos, análisis, aplicaciones y despliegue.
En el siguiente esquema definimos los 4 roles que deben de estar involucrados en un proyecto y sus acciones a cumplir en cada una de las dos vertientes:
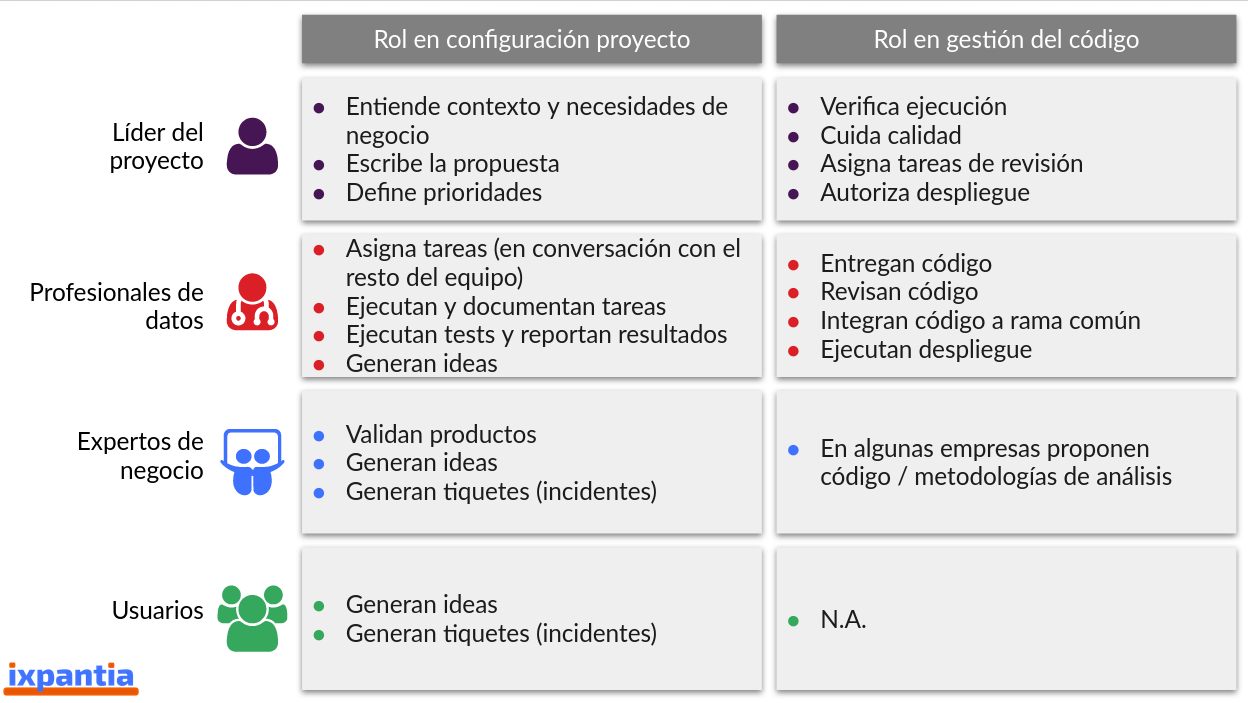
5.4.1 Líder del proyecto
Tiene la capacidad de llevar las tareas de gestión del proyecto. Esta es su principal tarea. Puede intervenir además en la ejecución de tareas que involucran código, revisión de entregas de tareas de código. Además debe de valorar las habilidades de los profesionales de datos para que las asignaciones de tareas sea de acuerdo al expertise que tiene cada uno de los miembros de equipo.
Al ser el líder debe de tomar desiciones que deben de ser traducidas de la necesidad del negocio a las tareas que hay que ejecutar e inclusive reconocer cuando hay una necesidad de pivotear el proyecto.
5.4.2 Profesional de datos
Son los encargados de la parte técnica del proyecto. Deben de colaborar junto con el líder del proyecto en la creación y designación de las tareas, ejecutarlas y documentarlas.
La documentación de tareas es esencial para no perder ideas o pensamientos de la razón de la tarea y el objetivo a cumplir con dicha tarea. Esto permite además arranques más rápidos cada vez que se regresa a trabajar en el proyecto o bien, permite una delegación más fluida del trabajo.
Deben de ser ordenados con el código, tanto con la calidad, la entrega y las versiones de este. Deben de coordinar estos esfuerzos con los demás miembros del equipo que son profesionales de datos.
Para dar soluciones a problemas durante la ejecución de proyectos deben de ser creativos y autodidactas para encontrar maneras de llevar a cabo los objetivos del proyecto. Así mismo deben de reconocer sus debilidades y si las tareas que tienen a cargo pueden ser resueltas con mayor rapidez o mejor técnicas por un compañero, delegarla.
Parte importante es la comunicación. Tanto para explicar en términos no técnicos las soluciones basadas en código, como para explicar al líder del proyeto el estado en la ejecución de tareas.
5.4.3 Experto de negocio
Su rol se encuentra principalmente en validar los productos de datos que genera el equipo, su aplicación a la solución de problemas encontrados en el negocio y cómo sacar ventaja de estos.
Así mismo, su expertise en el negocio les da la facultad de proponer ideas que les dé una ventaja en el mercado a través del uso de datos. Parte de su responsabilidad es comunicar puntualmente
5.4.4 Usuarios
Los usuarios están representados generalmente por la parte del cliente que en última instancia estarán haciendo uso del producto de datos. Su validación de la funcionalidad del producto de datos también es fundamental para que el proyecto sea considerado exitoso.
Sus intervenciones no son regulares. Son puntuales en momentos del proyecto que hay entregas intermedias (o la final) para que puedan dar retroalimentación en cuanto a la funcionalidad y su aprovechamiento del producto.
5.5 Tipos de documentación
Hemos hablado de que una parte esencial en el desarrollo de proyectos es la documentación, la cual tiene que ser válida para que la comunicación entre miembros del equipo (actuales, pasados y futuros) puedan saber de qué trata el proyecto y el estado de las tareas.
Esta documentación estará dirigida para los involucrados en el proyecto con sus distintos roles, desde el programador hasta el experto de negocio.
5.5.1 Documentación general del proyecto
Por documentación general del proyecto nos referimos a toda aquella documentación que utilizamos para la gestión del proyecto como por ejemplo notas de trabajo semanales que validan progreso de las tareas y el estado de las mismas hasta inclusive lo que es la propuesta del proyecto. Por documentación específica al código hacemos referencia a lo que es el LEEME (README) de los repositorios, los tiquetes e inclusive comentarios en el mismo código.
5.5.1.1 Documentación general
Dentro de esta tenemos los siguientes:
- Notas internas: documentos internos del grupo de trabajo para
- Propuesta del proyecto: Documento que plasma objetivos del proyecto, el alcance y lo que está fuera de dicho alcance.
- Notas de trabajo: Notas semanales que registran el estado de las tareas y el grado de completitud de las mismas.
- Hojas de cálculo: Para documentar diagramas de Gantt, contactos puntuales en el proyecto y otra información que se visualiza y ordena mejor en este tipo de archivo.
5.5.1.2 Documentación del código
- README: Documento para cada uno de los repositorios que son parte del proyecto. Deben de contener la información necesaria que explique la estructura del proyecto y los pasos necesarios para echarlo a andar.
- wiki: Documentos de referencia del proyecto que contienen resultados de análisis, explicaciones detalladas de procedimientos y otros archivos de consulta para usuarios que pueden tomarlo paso a paso para comprender aspectos de las tareas y resultados.
- Tiquetes/issues: Los tenemos mediante el sistema de gestión de repositorios de código en donde podemos anotar de manera muy específica las tareas con las asignaciones de quien las debe de cumplir